人工智能研究院杨耀东课题组TorchOpt开源项目被PyTorch纳入生态
2023/12/16 信息来源: 人工智能研究院
编辑:燕元 | 责编:山石可微编程在高级语言中实现了自动计算导数,从神经网络的反向传播到贝叶斯推断和概率编程,可微编程的广泛应用极大地推动了ML及其应用的进步。它实现了高效且可组合的自动微分(AD)工具,为可微优化[1, 2]、模拟器[3, 4]、工程[5]和科学[6]的发展铺平了道路。不断涌现的可微优化算法凸显了可微编程的核心地位。
近日,北京大学人工智能研究院杨耀东课题组主导的开源项目TorchOpt,一款基于PyTorch的高效可微优化库,被PyTorch官宣纳入生态,并被机器学习期刊Journal of Machine Learning Research(JMLR)接收。

PyTorch官宣将TorchOpt纳入生态
TorchOpt是一个基于PyTorch的库,其统一的编程抽象、高性能的分布式执行运行时以及对多种微分模式的支持,为可微优化带来了革命性的变革。(TorchOpt项目在GitHub上的地址https://github.com/metaopt/torchopt)
TorchOpt具有以下三种特性:
●多样性:TorchOpt包含三种微分模式——显式微分、隐式微分和零阶微分,满足各种可微优化需求。
●灵活性:TorchOpt提供功能和面向对象的API,以满足不同用户的需求。您可以使用类似于JAX或PyTorch的风格实现可微优化。
●高效性:TorchOpt提供CPU/GPU加速的可微优化器、基于RPC的分布式训练框架以及快速树操作,极大地提高了双层优化问题的训练效率。
TorchOpt融合了两个关键方面——统一且富有表现力的可微优化编程抽象和高效分布式执行运行时。
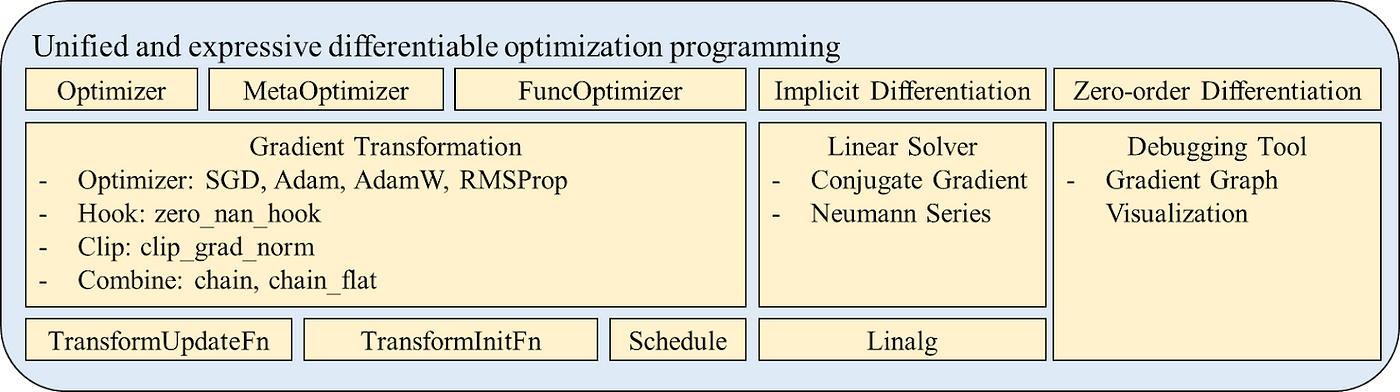
统一且表达性强的可微分优化编程抽象
TorchOpt提供了一种统一的编程抽象,可以高效地定义和分析可微优化程序,适用于显式、隐式和零阶梯度。
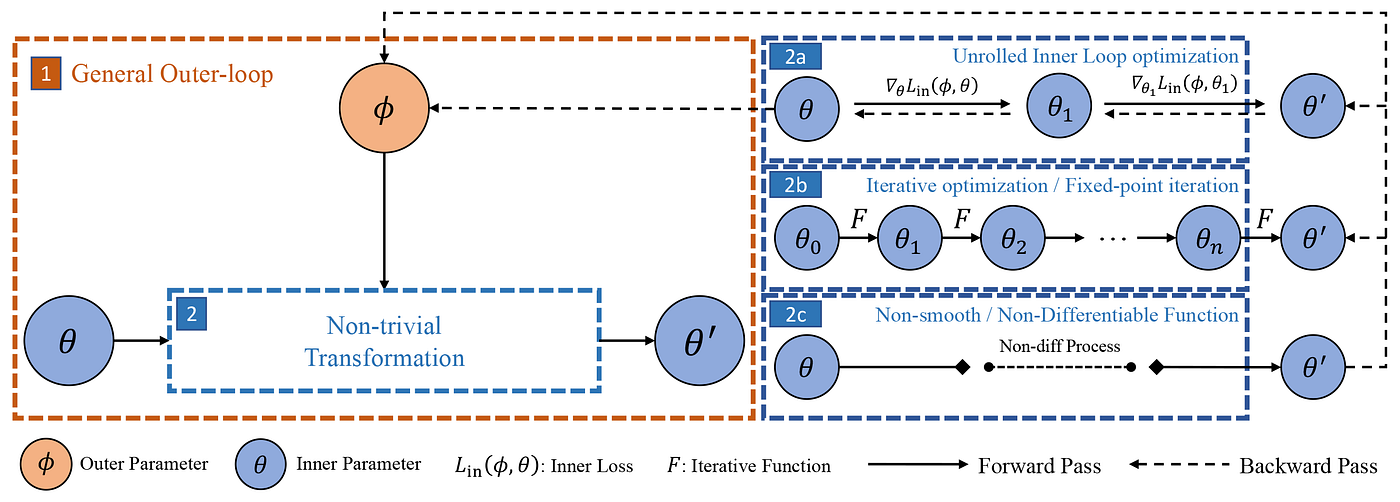
TorchOpt的微分模式图。通过将问题构建为一个可微分问题,TorchOpt为反向传播提供了自动微分支持(虚线所示)
TorchOpt的微分范式通过将问题表述为可微问题,为反向传播(虚线)提供AutoGrad支持。
TorchOpt提供了一系列从低级到高级,以及函数式(Functional Programming)和面向对象(Object Oriented Programming)的程序接口,使用户能够将可微优化纳入PyTorch生成的计算图。具体来说,TorchOpt支持处理可微优化问题的三种微分模式:
(i)显式梯度用于展开优化;
(ii)隐式梯度用于基于方程求解的迭代优化;
(iii)零阶梯度估计用于非光滑/非可微函数的优化。

TorchOpt支持处理可微优化问题的三种微分模式
TorchOpt提供了高性能的运行时和分布式训练支持,包含了多种加速解决方案,支持GPU和CPU上的快速微分,并具有多节点多GPU的分布式训练功能。下图显示了TorchOpt与其他基线在CPU/GPU加速算子和分布式训练方面的比较。
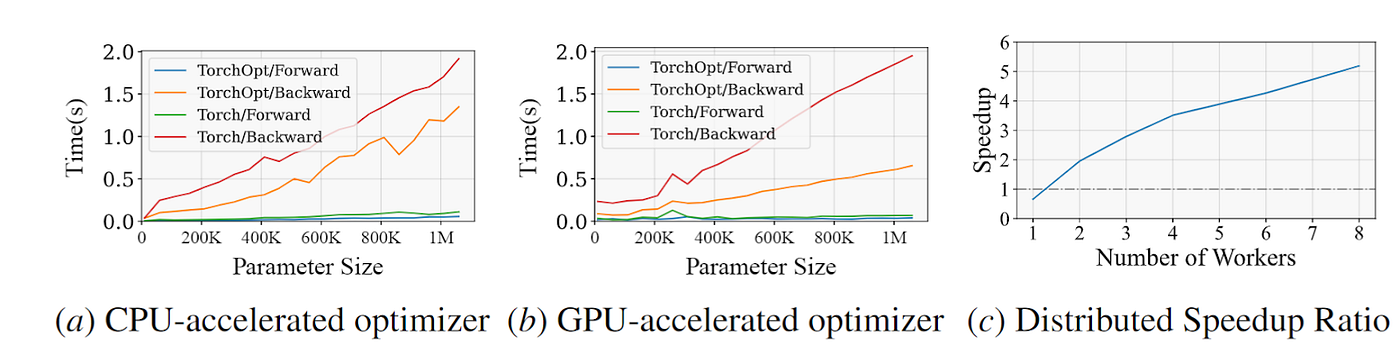
TorchOpt与其他基线在CPU/GPU加速op和分布式训练方面的比较
上图中显示TorchOpt的性能,(a)和(b)是不同参数大小下TorchOpt和PyTorch的前向/后向时间(Adam 优化器)比较,(c)是使用 RPC 分布式框架的多 GPU 加速实现与顺序实现的训练加速比。
对于PyTorch研究人员和开发者,TorchOpt的特性使其能够高效地声明和分析各种可微优化过程。
TorchOpt是一个新颖且高效的基于PyTorch的可微优化库。本研究的实验结果突显了TorchOpt作为支持PyTorch中具有挑战性的梯度计算问题的用户友好、高性能且可扩展库的潜力,并计划未来支持更复杂的差分模式,涵盖更多非平凡的梯度计算问题。TorchOpt已经被证明对元梯度研究非常有用,在作为更广泛范围的可微优化问题的关键自动微分工具上具有发展前景。
本项目研究论文的四位一作作者,分别是来自爱丁堡大学的任杰、伦敦大学学院的冯熙栋、新加坡国立大学的刘博,以及北京大学的潘学海。该项目的通讯作者分别是爱丁堡大学的麦络助理教授和北京大学的杨耀东助理教授。
转载本网文章请注明出处